Etterlengtet Native Write-back i Power BI og Microsoft Fabric – slik gjør du det
Native Write‑back, eller tilbakeskriving på godt norsk, er endelig tilgjengelig i Power BI og Microsoft Fabric. Nå kan du skrive data direkte til dataplattformen og se endringene umiddelbart der du jobber. Det gir en enklere arkitektur, færre feilkilder og en mer presis dataplattform og sanntidsrapporter i Power BI.
I denne artikkelen viser vi hvordan du setter opp Native Write‑back på en trygg og effektiv måte, hvilke avklaringer du bør gjøre i modelleringen, og hvordan du bygger en løsning som både utviklere og brukere kan stole på.
23.02.2026
Lesetid: 7 min

Sebastian Skaiaa, Datainnsikt-konsulent i Crayon Consulting
Tilbakeskrivingsfunksjonalitet har lenge vært etterspurt i Microsoft Power BI. For dem som har tatt i bruk Microsoft Power Platform, har Power Apps ofte blitt brukt for å dekke behovet. Men flere teknologikomponenter fører til økt kompleksitet og vedlikehold. Samtidig som du introduserer andre typer lisenser. Denne barrieren gjør at mange aldri kommer i gang.
Nå gir ny funksjonalitet i Power BI og Microsoft Fabric deg endelig muligheten til å jobbe smartere og mer effektivt med data – alt samlet i én Fabric-kapasitet.
Hvorfor er Native Write-back nyttig i en dataplattform?
Native Write-back i Power BI lar brukere oppdatere, legge til eller slette data direkte. Denne funksjonaliteten beriker samarbeid og beslutningsgrunnlag med sanntidsoppdatering.
Som datainnsikt-konsulent jobber jeg, Sebastian Skaiaa, med data og kjenner til verdien av interaktivitet og hurtige oppdateringer for å se hvordan input påvirker datagrunnlaget. Dette gir følelsen av fleksibilitet og troverdighet, noe jeg mener mange forbinder med brukeropplevelsen i Microsoft Excel. Det er uten tvil at Native Write-back gjør det mer effektivt å jobbe med data i Power BI.
Skriv data direkte med Translytical Task Flows og User Defined Functions
I 2025 ble Translytical Task Flows og User Defined Functions introdusert i forhåndsversjon i Power BI og Microsoft Fabric. Funksjonene er brukerdefinerte og muliggjør tilbakeskriving i sanntid til OneLake. De er tilgjengelige for alle med siste versjon og kan brukes til flere ulike operasjoner, inkludert tilbakeskriving fra Power BI til en Microsoft Fabric-database. Kombinerer du dette med DirectQuery, får du en kraftfull måte å berike datagrunnlaget på, samtidig som endringer blir synlige umiddelbart.
Korte ordforklaringer
Hva er OneLake?
OneLake er organisasjonens lagringsområde på tvers av de ulike komponentene i Microsoft Fabric. Øverste nivå for Fabric-data er organisasjonens tenant og OneLake du kan tilgangsstyre med arbeidsområder.
Hva er Translytical Task Flow?
Translytical Task Flow lar brukere automatisere handlinger som oppdatering, legge til data eller sette opp arbeidsflyter som aktiveres i andre systemer.
Hva er User Defined Functions?
User Defined Functions lar brukere lage Python-baserte funksjoner som kan bli aktivert på tvers av komponenter i Microsoft Fabric og fra eksterne applikasjoner.
Hva er DirectQuery?
DirectQuery speiler tabellen i datakilden direkte, i motsetning til import som krever oppdatering av underliggende semantisk modell.
Hvordan lykkes med Native Write-back i Microsoft Fabric?
For å få til sømløs tilbakeskriving i Fabric er det avgjørende med tydelige definisjoner i SQL-databasen, særlig knyttet til datatyper og samsvar mellom databasen og Power BI-modellen. Uten klare rammer for struktur og forvaltning risikerer du å bygge løsninger som er vanskelige å vedlikeholde. Derfor bør du etablere tilbakeskrivingsfunksjonene på en måte som sikrer sporbarhet, sikkerhet og god tilgjengelighet i dataplattformen.
Hva trenger du for å komme i gang?
Nå som SQL-database, User Defined Functions og Translytical Task Flows er tilgjengelig i Microsoft Fabric, kan du med tre steg komme i gang med tilbakeskriving direkte fra Power BI:
1. Opprette en SQL-database i Fabric
2. Opprette en brukerdefinert funksjon
3. Oppdatere Power BI med Translytical Task Flows
1. Opprett SQL-database i Fabric
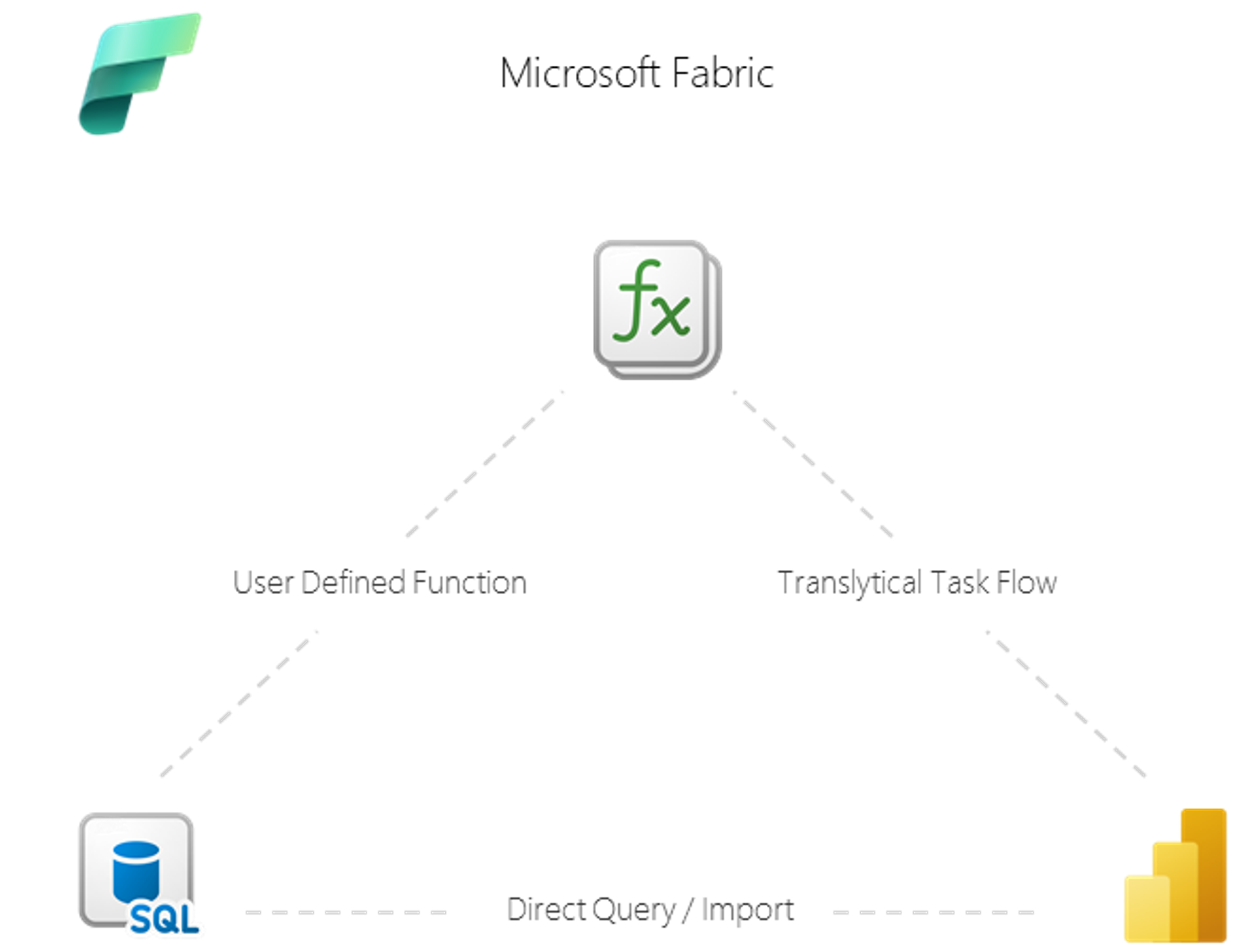
Native write-back i MS Fabric: Figur 1.1 Oversikt struktur dataflyt
Først må vi opprette en SQL-database og en tabell i Microsoft Fabric. I mitt eksempel har jeg tatt utgangspunkt i en forenklet kommentarløsning på prosjekter på en gitt periode. Ettersom vi nå har støtte for SQL-databaser i Fabric, kan vi også definere primærnøkler og legge på indeksering ved større datasett.
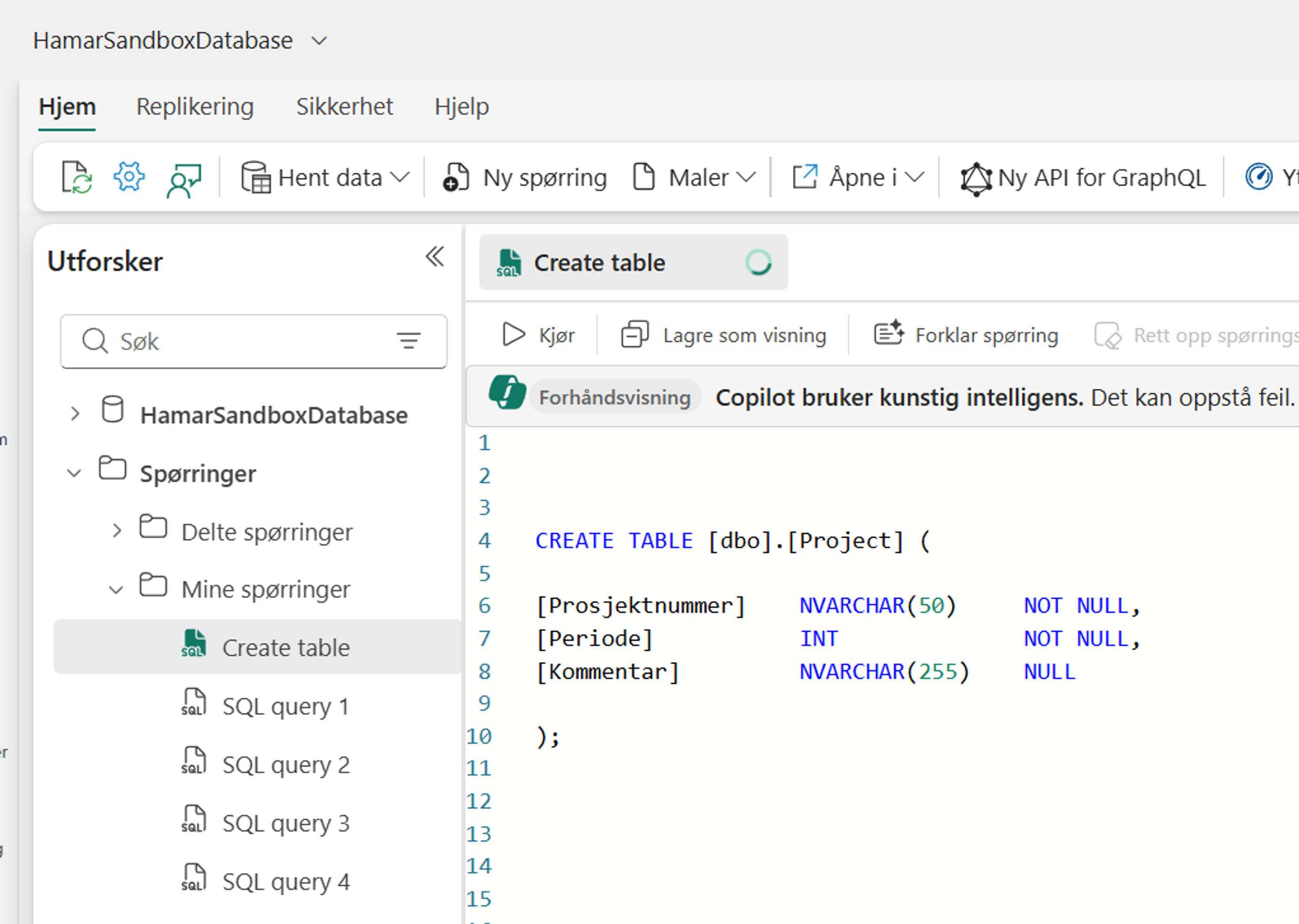
Nativ write-back i MS Fabric: Figur 1.2 – SQL kode for opprettelse av tabell på SQL-database
2. Opprett en brukerdefinert funksjon
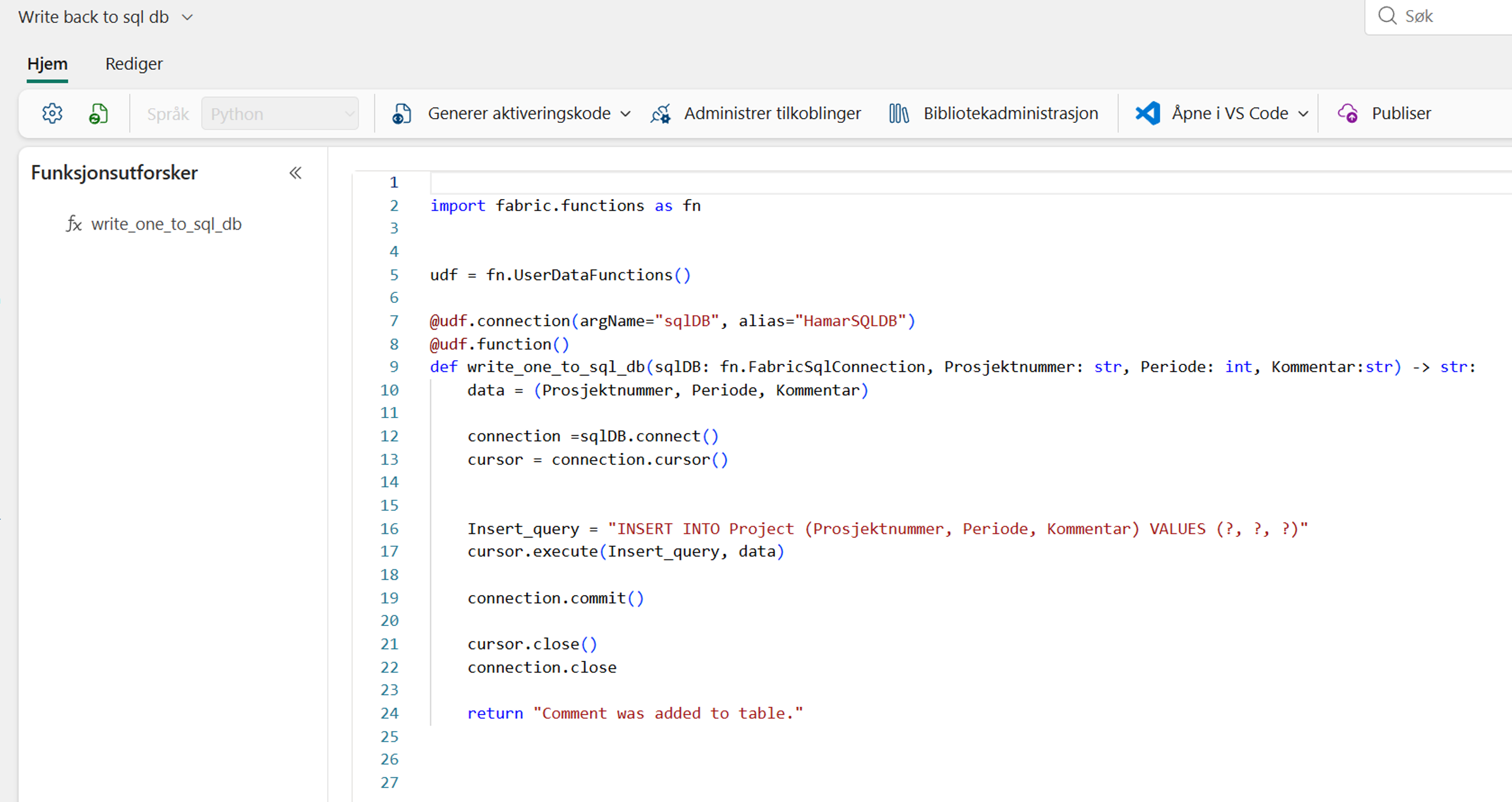
Når tabellen i SQL-databasen er opprettet, kan vi lage en brukerdefinert funksjon i Microsoft Fabric. Brukerdefinerte funksjoner er Python-basert og bruker SQL for å gjøre oppdateringene på databasen.
Under administrer tilkoblinger i funksjonen har jeg lagt opp en kobling til SQL-databasen som jeg har gitt alias HamarSQLDB og er koblet til kilde HamarSandboxDatabase som er navnet på SQL-databasen.
Klikk på Administrer tilkoblinger
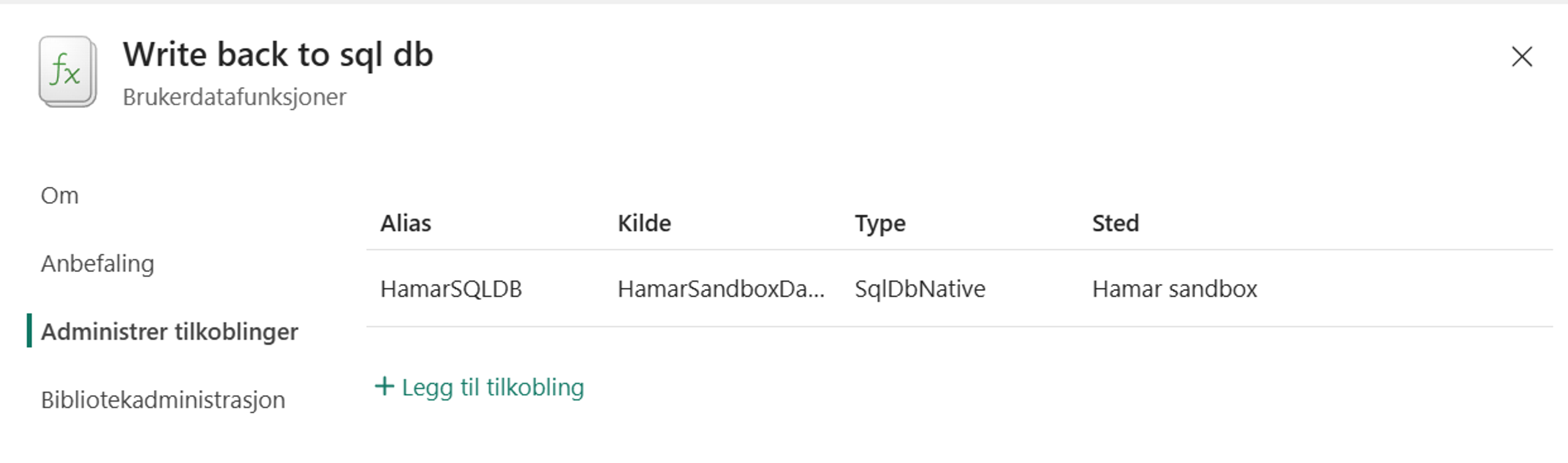
Skjermbilde brukerdatafunskjoner og tilkoblinger i MS Fabric
Under Rediger > + Sett inn eksempel finner du flere eksempler på hvordan du setter opp ulike funksjoner mot Warehouse, Lakehouse, SQL-database osv.
Skjermbilde MS Fabric: Write-back i sql database
I bildet under ser du koden for den brukerdefinerte funksjonen.
3. Oppdater Power BI med Translytical Task Flows.
File > Options and settings > Options > Preview features.
Når funksjonen er laget kan vi opprette en knapp i Power BI som aktiverer funksjonen og utfører operasjonen. Funksjonen legges til under handlinger på knappen.
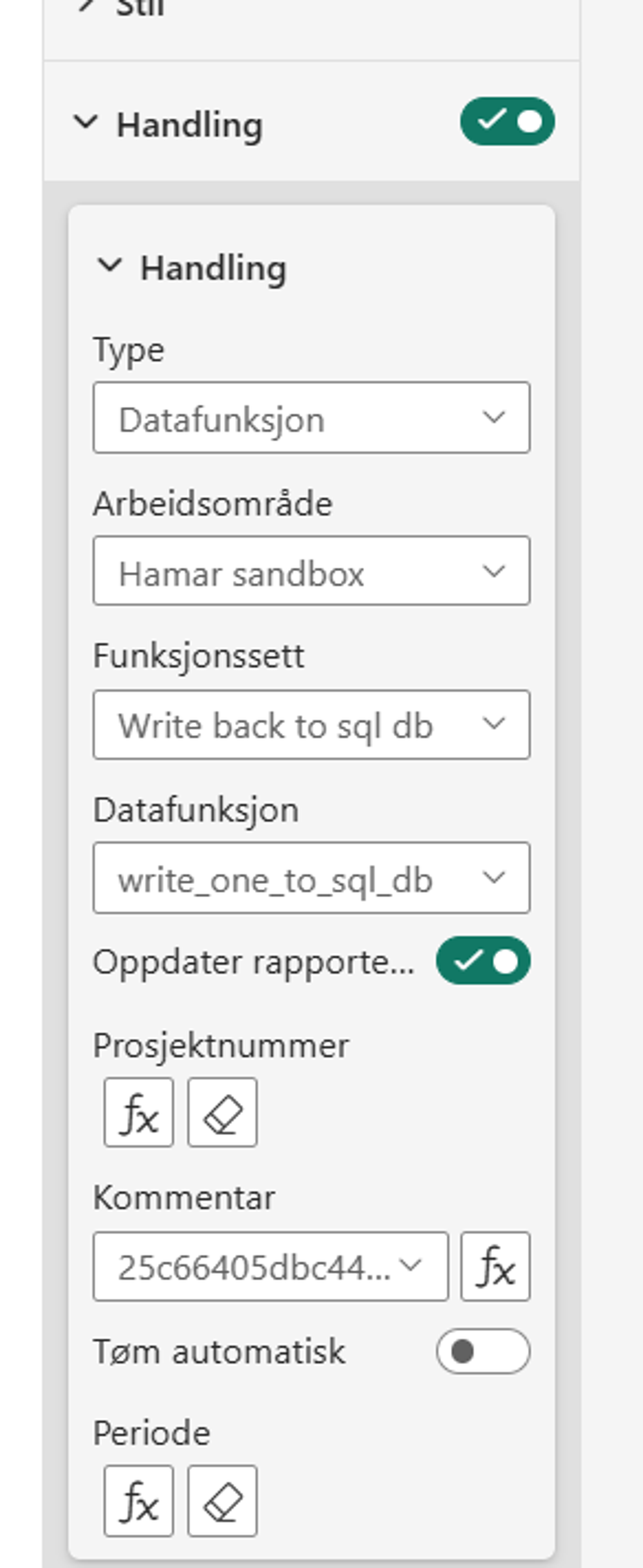
Det som er elegant er at vi kan benytte dax-kalkulasjoner som input til de forskjellige parameterne. Dette har jeg gjort på prosjektnummer og periode. Hvis jeg for eksempel benytter en kalkulasjon PERIOD SELECTED VALUE = SELECTEDVALUE(Dim_Date[YearPeriod]), så er det den perioden jeg velger i Power BI-rapporten som jeg skriver til. Kalkulasjonen legger jeg til på fx-knappen.
Klikk på "FX"-knappen for å kalkulere
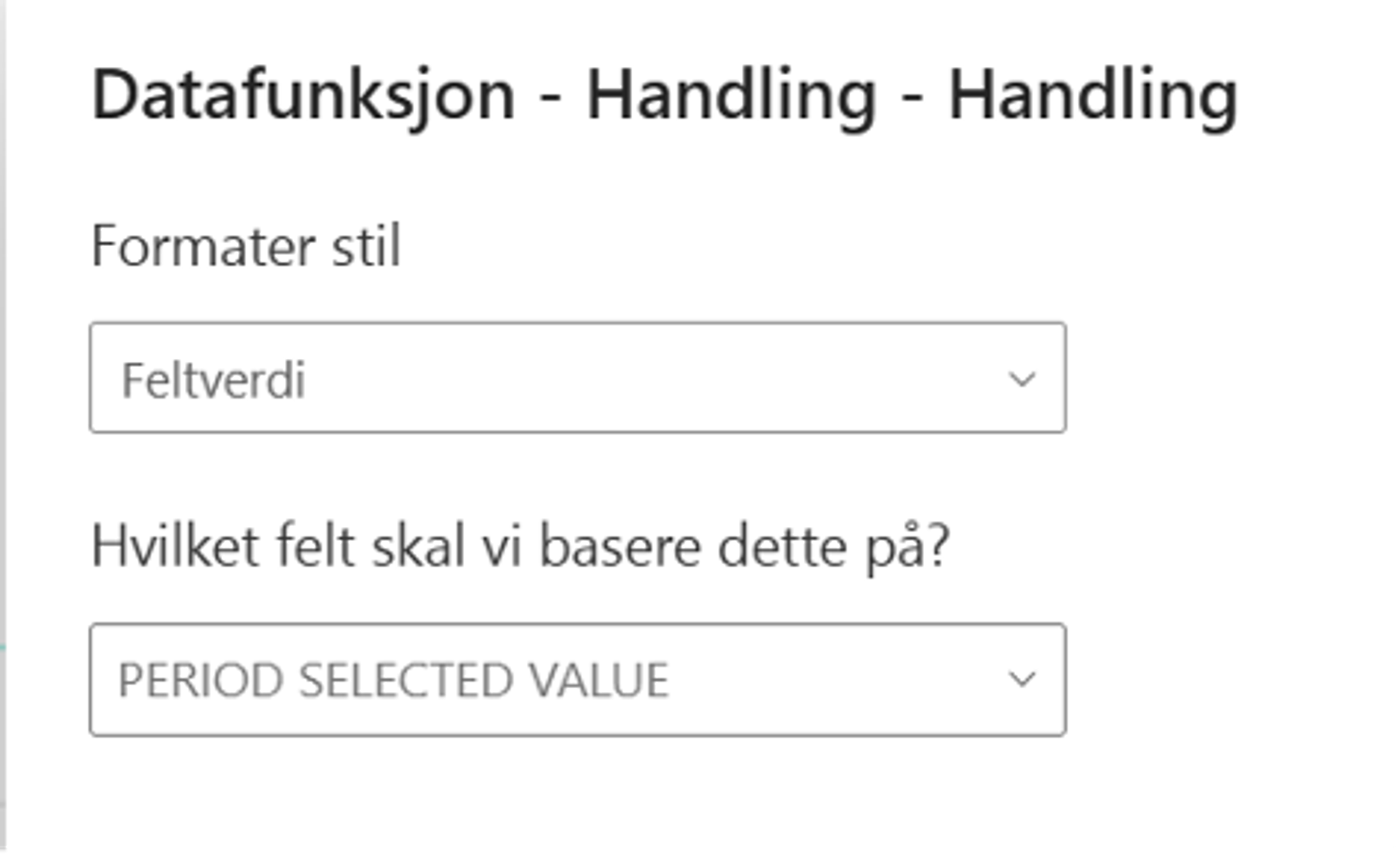
Kommentar input er henvisning til en spesial visualisering som du får mulighet til å bruke ved aktivering av Translytical Task Flows.
Bygg visualobjekt
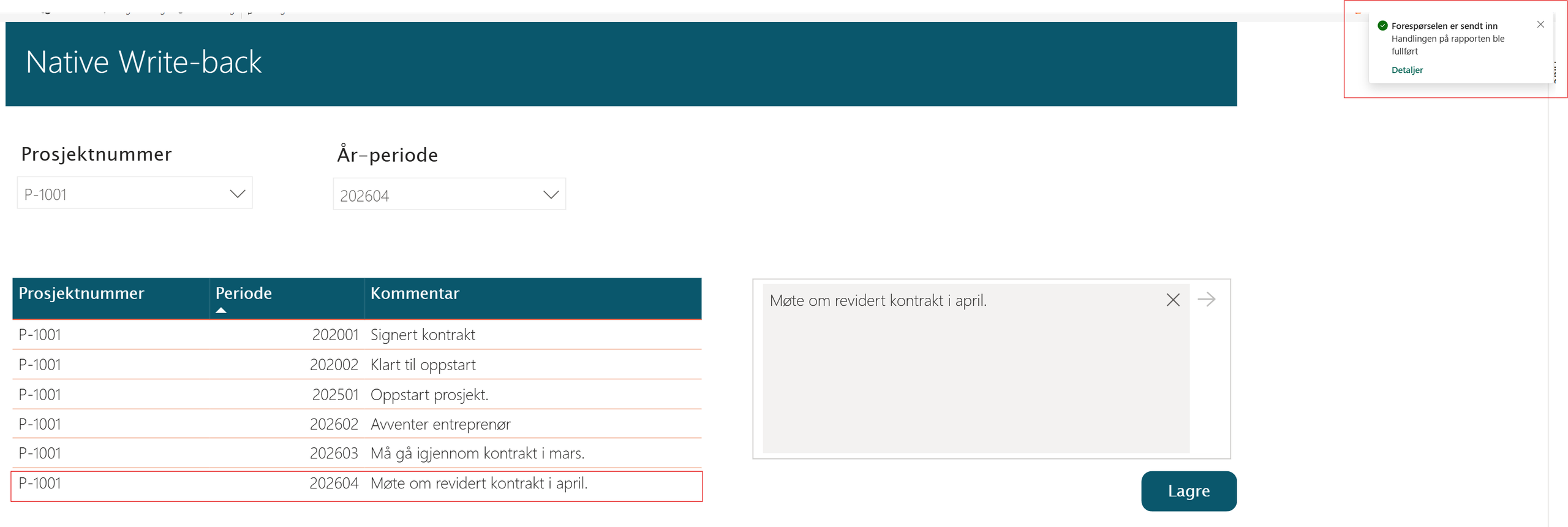
Tabellen i rapporten er DirectQuery som oppdaterer seg automatisk ved vellykket operasjon.
Under ser du verdens beste Power BI rapport, hvor vi kan filtrere på prosjekt, periode og skrive kommentar. Tabellen er en DirectQuery, som automatisk skal reflektere innholdet i tabellen vi lagde på SQL-databasen.
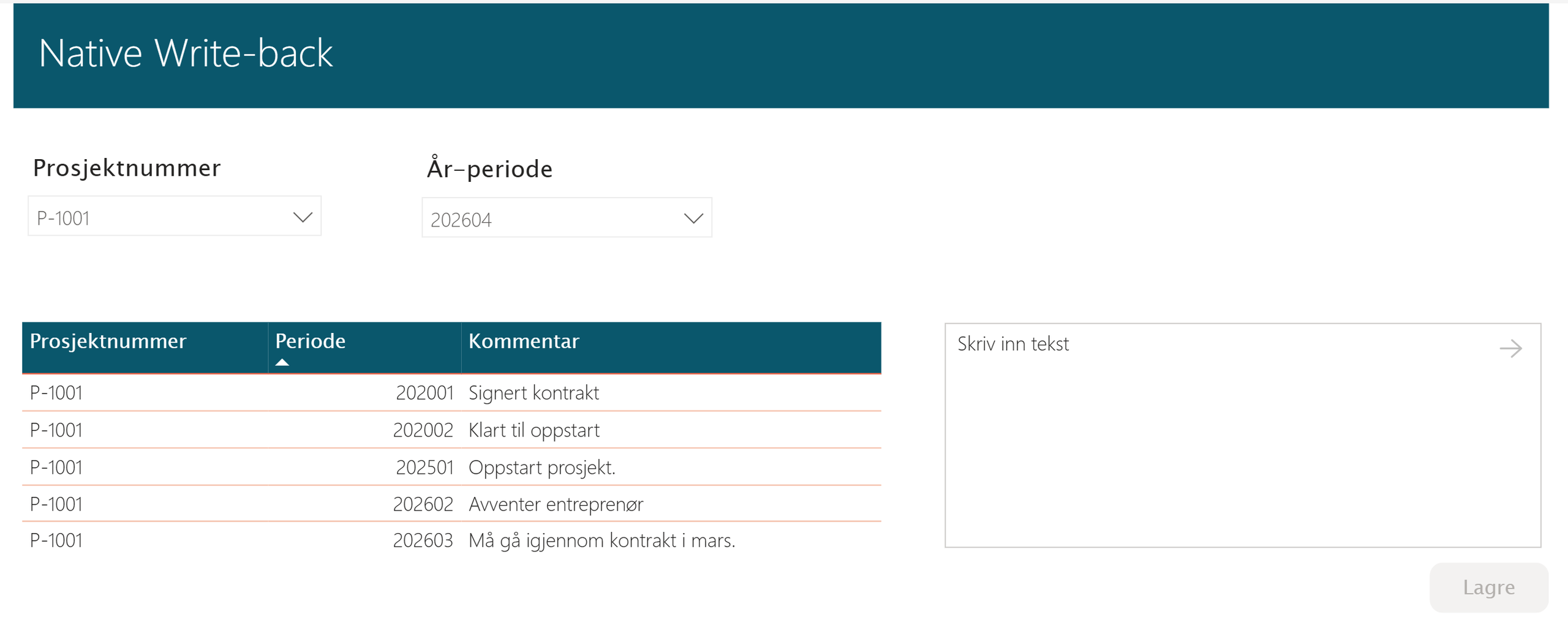
Power BI rapport med DirectQuery-tabell
I kommentar-boksen skriver jeg en kommentar. Når denne er lagt inn, vil jeg kunne trykke på lagre-knappen og funksjonen blir aktivert.
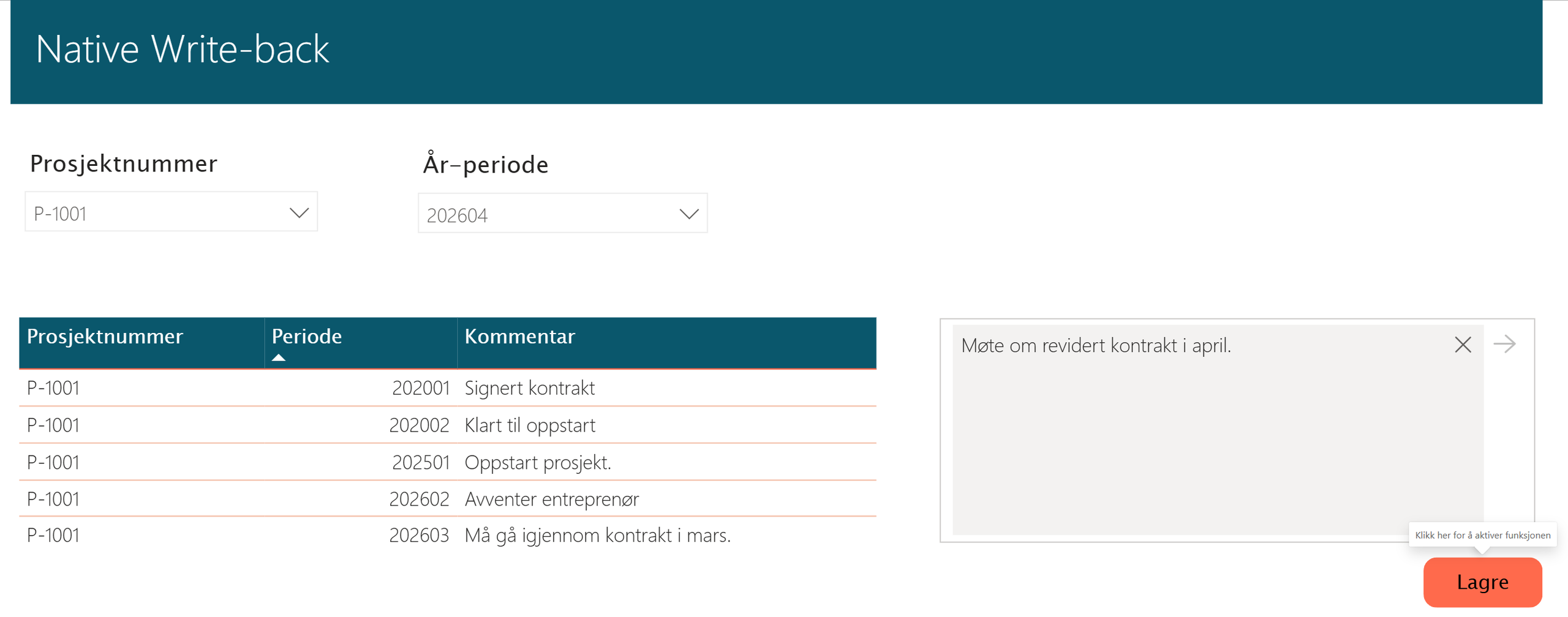
Når operasjonen utføres og den blir godkjent, vil du få informasjon om dette oppe i høyre hjørnet på rapporten. Deretter vil kommentaren bli reflektert direkte i tabellen.
Tips til hvordan få Native Write-back-funksjonalitet til å fungere
Start smått med enkle prosesser
Begynn med å teste de enkle prosessene, for eksempel en type kommentar-løsning. Skaler og øk kompleksiteten når dere ser verdien av dette.
Marker dataene tydelig
Unngå datakaos ved å tydelig markere data som kommer fra Power BI-rapportene. Når vi blander data som hentes ut til dataplattform fra eksterne kildesystemer med data som kommer fra Power BI-rapporter, er det viktig å markere hvor data kommer fra. Dette kan være så enkelt som å ha spesifikke skjema på tabellen powerbi.project, eller at du har meta_source og meta_ingested_datetime kolonner som forteller at denne raden kommer fra Power BI og når den ble oppdatert.
Oppsummering
Med Translytical Task Flows og User Defined Functions har Microsoft gjort det mulig å skrive data tilbake til OneLake i Fabric. Ved å kombinere dette med DirectQuery, ser du endringer umiddelbart i Power BI-rapportene. Dette skaper fleksibilitet, tillit og god brukeropplevelse.
For at løsningen skal fungere optimalt, må du ha tydelige datadefinisjoner, struktur og god forvaltning for å sikre sporbarhet, sikkerhet og kvalitet. Min anbefaling er å starte enkelt og deretter øke kompleksiteten gradvis. Samtidig er det viktig å tydelig markere data som skrives tilbake fra Power BI, slik at du skiller disse fra øvrige data som kommer fra andre kilder i plattformen.

Sebastian Skaiaa
Senior datainnsikt-konsulent i Crayon Consulting.
Sebastian jobber som rådgiver, utvikler og konsulent innen datainnsikt på Hamar og er opptatt av å hjelpe kunder hente ut verdi av teknologi og data. Med sertifisering innenfor blant annet Microsoft Fabric har han god erfaring med å hente inn, strukturere og visualisere data i Power BI og bruker SQL og Python til å automatisere dataflyt.
Vil du slå av en prat med meg?

Sebastian Skaiaa
Datainnsikt-konsulent | HamarRelaterte saker

08.01.2026
Slik offentliggjør du data effektivt med Power BI
Trenger du å publisere Power BI-rapporter åpent uten innlogging? Slik bruker du Publish to web trygt.
23.02.2026
Etterlengtet Native Write-back i Power BI og Microsoft Fabric – slik gjør du det
Skriv data direkte til dataplattformen og se endringene umiddelbart – hvordan sette opp Write‑back på en trygg og effektiv måte

06.06.2025
Anerkjent som Microsoft Fabric Featured Partner
Har spilt en sentral rolle i å få de første kundene i produksjon i Norge.